
What’s in a Metric? A lot, it would seem
Some time back, I was reading a WSJ article about a Chinese Finance firm that used AI to develop predictors on who was a good candidate for loans. Among the thousands of factors, what was interesting to me is they determined the average battery charge on someone’s phone were deemed safer credit risk. People with lower average charge were much less likely to pay back their loans than people that kept it high.
What does this have to do with bias and fairness in AI? It turns out in the real-world people and businesses rely on behavioral proxies for several things. AI make them make real world contracts a lot fairer than some of the existing methods. We now can stop relying on behavioral targeting and proxy discrimination, and instead rely on detailed data from smartphones such as a user’s messaging and browsing activity to determine whether or not someone is a good lending risk, what rates to charge them etc.
The fundamental problem in any business or commercial transaction is what an economist would term asymmetric information, and the associated problem of moral hazard. There is an asymmetry of information between the borrower and lender since the lender does not know the borrower’s type. Similarly, when you hire a contractor to build an extension in our home, you don’t know how much effort the contractor will put in in keeping costs low for you. Or alternately when an insurance company offers you a clause protecting you against damage, the insurance company does not know how much effort you could exert in driving carefully. It could be very well be that an insurance contract that will protect against collisions might encourage more risky and aggressive driving behavior.
Moral hazard occurs when one party to an economic transaction changes their behavior to the detriment to the other. Moral hazard occurs as a result of asymmetric information when one party (the party that is offering the contract) does not know the behavior of the other party (the party that accepts a contract). Protections against liability might encourage risky behavior, and it could be those individuals that are more risk-taking may be the ones who would opt for the more comprehensive coverage contracts (and willing to pay a premium for it). Alternately, knowing they are protected against accidents might induce people to engage in more risky behavior.
In the absence of actual information about borrower behavior or insurer behavior, companies end up relying on many behavioral proxies for risk. Insurers look at historical records of prospective clients as well as demographic characteristics in assessing who they should provide insurance to. In a seminal paper, Nobel Prize winning economist Kenneth Arrow argued that under some conditions, such as in the market for healthcare, the asymmetric information – arising from patients’ lack of understanding about healthcare -and the difficulty of assessing the quality of healthcare – results in a failure of efficient markets.
While we have a comparatively better understanding of information asymmetries now, some of the fundamental challenges of information problems in markets remain. A central problem remains that buying insurance is more attractive for more risk-taking individuals (or in the case of health insurance, sicker individuals would benefit). Insurers employ measures such as deductibles and co-payments to protect themselves against some types of moral hazard. Governments could underwrite some types of insurance. Again, health insurance is an example where a public health system guarantees a certain amount of coverage.
The arcane world of insurance and contracting can be completely mystifying to anyone who is not an actuary. Ben Bernanke was denied a mortgage refinance request when he ended his term as chairperson of the Federal Reserve. The reason for that is -the automated systems that decide whether someone is eligible for a loan are usually primed to look at someone who changed jobs and/or an irregular income (unpredictable revenue from speeches and book advance payments, even if it is higher than his more predictable salary as chairperson of the Federal Reserve). While such types of behavioral proxies may result in a famous and affluent person such as Ben Bernanke being denied a refinance, it is most frequently the case that such behavioral proxies could be much harsher on gig workers, temp workers, and others without a steady stream of income.
Now now digital platforms have measures to mitigate asymmetry through continuous monitoring and real time feedback and providing for mechanisms such as seller rating. The sources of asymmetric information that were previously unobserved can be observed and monitored in real time. In rural India, delinquency in payments can sometimes have mundane reasons, such as borrowers forgetting their due dates or failing to withdraw cash. A service called KisanPay (which means Farmer Pay in Hindi) uses AI to provide automated voice calls, enabling farmers to choose when they can repay loans and how. AI assisted chatbots or agents can be used to deploy behavioral nudges based on behavioral cues gathered from data, reducing some of the information asymmetry in lending.
Digitization, Moral Hazard and Bias Mitigation with AI
So, does the widespread availability of data and ease of monitoring enabled by AI mitigate biases? A study of Uber drivers provides a clue. The study by Meng Liu, Erik Brynjolfsson and Jason Dowlatabadi examined driver detours, which are defined as the extra distance a driver adds to the fastest route between two points. In other words, is there a difference in behavior between a taxi driver and an Uber driver who drive between the same two destinations at say the same time? By measuring detours, we can examine if a systematic difference exists between taxi drivers and Uber drivers (since the different routes they take is a good way to assess the underlying costs and benefits to them). Since Uber relies on ratings of drivers, a shared GPS navigation and technology-enabled monitoring and real-time feedback, which increase the costs for drivers from engaging in moral hazard, Uber drivers would be less likely to take inefficient routes than comparable taxi drivers. The study did indeed find that to be the case. Uber drivers were less likely to engage in driver detours. With fears of algorithmic bias and bias in automated decisions, we also have the hopeful possibility that some types of biases are mitigated by AI.
One such example is that of telematics, where in-vehicle telecommunication devices have detailed logs of driver behavior on aspects such as GPS coordinates, rapid acceleration, hard braking, air bag deployment etc. While this may appear intrusive, it is the case that the market for auto insurance has been difficult for younger and first-time drivers. Telematics will provide an opportunity for younger drivers to get fairer insurance terms. With the digitization and the parallel rise in algorithmic governance, AI based real time monitoring could replace earlier modes of behavioral proxies or methods of rewarding performance. There is at least some evidence that such type of monitoring behavior leads to safer driving.
To Predict, or Not to Predict?
Of course, using such automated systems to improve real-world outcomes means that we need to be extra sensitive to the hidden biases that underlie training data and training algorithms. When image labeling is suffused with biases, then autonomous driving vehicles and medical algorithms that depend on these labeled datasets will produce biased decisions. A study shows that Google Street View images from people’s houses can be used to determine how likely they are to be involved in a car accident. The researchers found that features visible on a picture of a house can be predictive of car accident risk, independently from traditionally used variables such as age or zip code.
Another type of bias which is especially insidious is black box training methods where we do not pay attention to how our methods of training end up reinforcing or amplifying biases. In a blog post titled “how to create a racist AI without training”, Robyn Speer identified how using sentiment scores for words can lead to more racist conclusions. A sentiment score of zero is neutral, while positive scores are associated with positive feelings and negative scores are associated with negative feelings.
Example from Twitter thread from @kareem_carr

Robyn Speer provided a similar example where using word embedding methods (a very popular approach in natural language processing) for restaurant reviews shows for example that Mexican restaurants were ranked lower. The reason for that is the AI was trained using words from the Internet, where the word “Mexican” can be used in conjunction with the word “illegal”, thereby creating an inference that Mexican is a synonym for something bad. It is possible to de-bias data with human intelligence, but we do need an awareness that our methods of training used by machine learning algorithms and methods of labeling data need to be bias-aware.
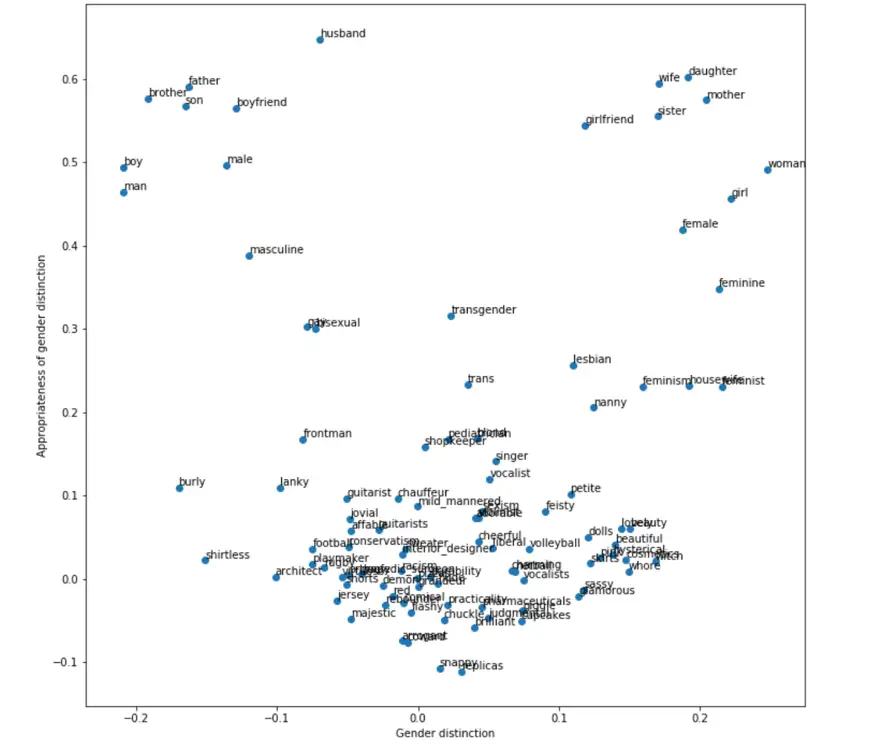
Word associations before de-biasing (example from Robyn Speer)
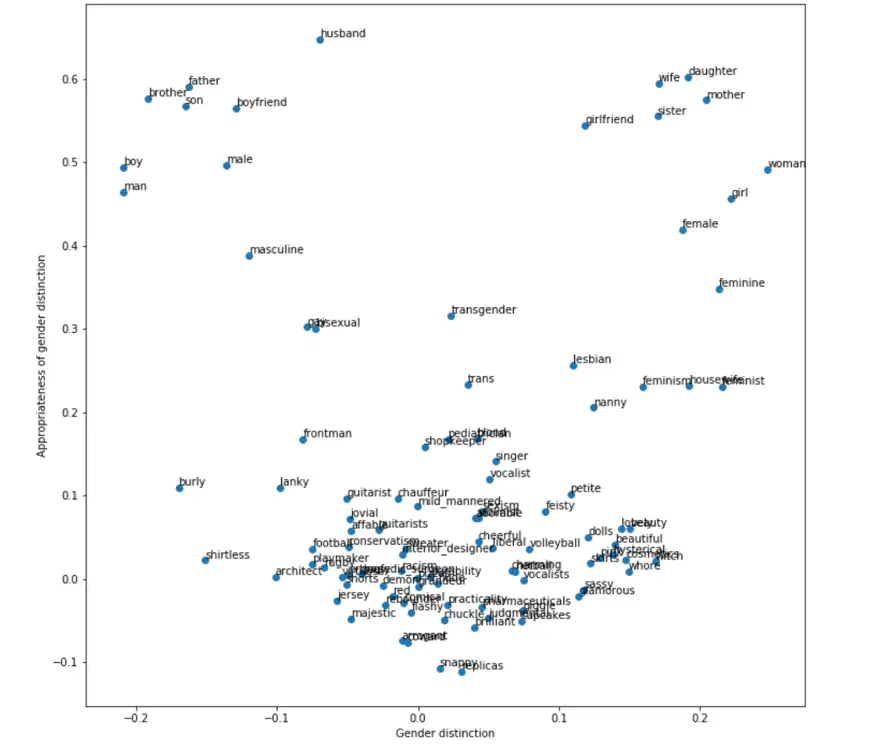
Word associations after de-biasing (example from Robyn Speer)
Summary
We now have an unprecedented ability to collect, analyze, and manipulate information from a wide range of sources. Every aspect of our life generates digital traces, and algorithms have been primed to spot every nuance or detail of our behavior and mine it for actionable insight. It is probably too late to stop this avalanche of digital information, nor reverse the move for businesses to micro target every aspect of our lives from the expanses of our digital selves that we lay bare. The ability with which businesses can understand this data is much more rapid than what each of us can easily comprehend, and it has far outpaced regulatory effects to stymie AI induced monitoring. While we need to be extra sensitive to label biases and training biases, it is important to keep in mind that better design of AI systems can mitigate some of the societal challenges from algorithmic harms.





